
原文链接:点我点我
Apache Mesos
Apache Mesos 是一个管理器,它通过分布式的应用或框架提供了一种高效的资源隔离和共享。Mesos 最初是由加州大学的伯克利分校开发的开源软件。它处于应用层和操作系统之间,使其易于部署,并使得在大规模集群环境中部署应用变得更高效。它可以在一个节点动态共享的池中运行很多应用。Mesos 的突出用户包括 Twitter、Airbnb、MediaCrossing、Xogito 以及 Categorize。
Mesos 利用了现代内核的特性 – Linux 中的 “cgroups” 和 Solaris 中的 “zone” – 来提供 CPU、内存、I/O、文件系统、机架位置等等的隔离。它最大的思想是形成异构资源的一个庞大集合。Mesos 介绍了一个称为资源提供的分布式的两层调度机制。Mesos 会决定给每个框架提供多少资源,而框架决定接受多少资源和在其上运行多少计算。这是一个轻量的资源共享层,通过给框架一个通用接口来访问集群资源,它使得细粒度的共享跨越了不同的集群计算框架。其想法是部署多种分布式系统到节点的一个共享池中,这样能够提高资源利用率。很多现代的工作负载和框架都可以运行在 Mesos 上,包括 Hadoop、Memecached、Ruby on Rails、Storm、JBoss Data Grid、MPI、Spark 和 Node.js,以及各种 web 服务器、数据库和应用服务器。
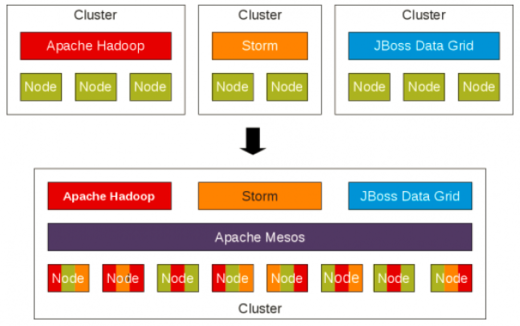
类似于在 PC 操作系统管理桌面电脑上的资源访问,Mesos 保证应用程序能够在集群中访问它们所需要的资源。不同于为应用的不同部分配置各种服务器集群的方式,Mesos 允许你共享服务器的一个池,它可以运行你应用程序的不同部分,它们不会相互干扰并能够根据需求通过集群分配资源。这就意味着,它能够很容易地切换资源,如果发生了严重的堵塞,它可以离开 framework1(例如,进行一个大数据分析)然后将它们分配到 framework2(例如,web 服务器) 中。这也减少了部署应用中的很多人为步骤,并能够自动转移工作负载,以提供容错和保持高的利用率。
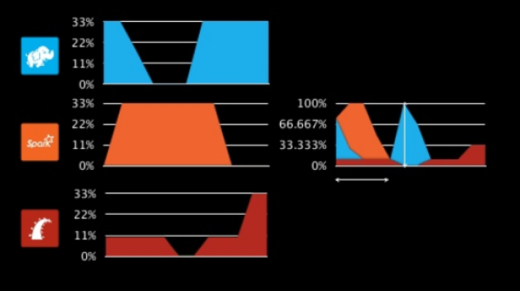
Mesos 本质上是一个数据中心内核 – 这意味着它是一个实际上将运行的工作负载彼此分离的软件。当这些任务实际运行时,它也需要额外的工具来使 engineer 获得它们在系统中运行的工作流并进行管理。否则,一些工作负载可能会消费所有的资源,或者重要的工作负载可能会与需要更多资源但不那么重要的工作负载发生冲突。因此 Mesos 需要的不仅仅是一个内核 – Chronos scheduler,一个 cron 的替代品,用于自动启动或关闭(并处理故障)运行在 Mesos 之上的服务。Mesos 的另一个部分是 Marathon,它提供 API 来启动、关闭和扩展服务(而 Chronos 可能是其中的一个服务)。
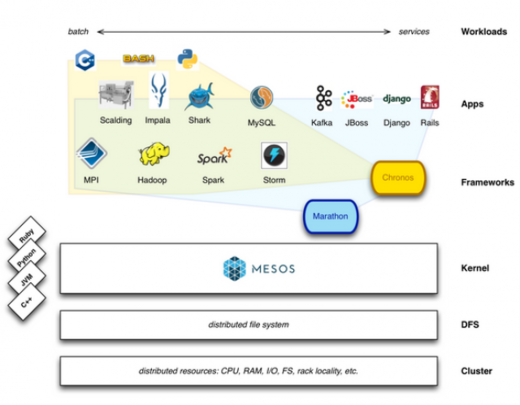
架构
Mesos 由管理运行在各个集群节点上的 slave 守护进程的 master 进程以及在这些 slave 上运行任务的 framework 组成。master 通过 framework 使用资源提供实现了细粒度的共享。每个资源提供是一个各个 slave 上空闲资源的列表。master 通过编制的策略,如公平共享或设置优先级,来决定为每个 framework 提供多少资源。为了支持一组不同内部框架分配策略,Mesos 允许组织者通过可插拔的配置模块定义他们自己的策略。
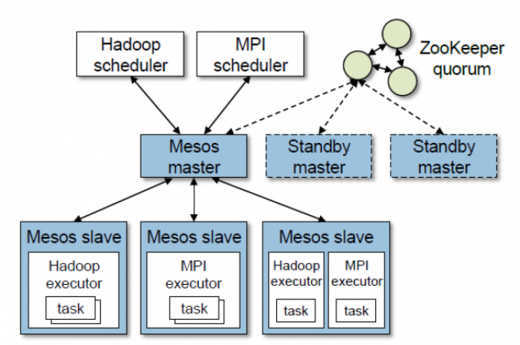
每个运行在 Mesos 上的框架由两个组件组成:一个由 master 注册的用于提供资源的 scheduler(调度器),以及在 slave 节点上启动来运行框架任务的 executor process(执行进程)。当 master 决定了提供多少资源给框架,framework 的 scheduler 就选择所请求的资源以使用。当 framework 接受了请求的资源,它会向 Mesos 传递一个它要启动的任务的描述信息。
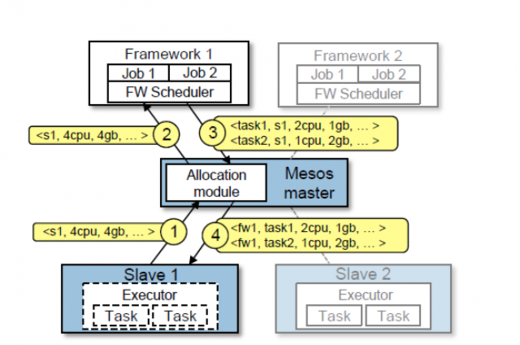
上图展示了一个框架如何调度并运行任务的示例。在第一步中,slave1 向 master 报告它有 4 个 CPU 和 4GB 的内存空闲。于是 master 调用了分配模块,告诉 framework1 可以提供所有可用资源。在第二步中,master 发送了一个描述了这些资源的资源提供给 framework1。在第三步中,framework 的 scheduler 回应了 master 一条关于在 slave 上运行了 2 个任务的信息,使用了 2 个CPU;1GB 内存和 1 个 CPU 用于第一个任务;2GB 内存用于第二个任务。最后,在第四步,master 发送任务给 slave,这个任务要求分配合适的资源给 framework 的 executor,executor 将启动两个任务(用虚线描绘的部分)。由于 1 个 CPU 和 1GB 内存仍然空闲,此时分配模块会将他们提供给 framework2。此外,当任务完成而资源变为空闲时,资源提供进程会重复上述步骤。
而由 Mesos 提供的轻量接口允许它扩展并允许 framework 独立发展。framework 会拒绝不满足其限制的提议并接受那些能够满足的。由其是我们发现了一个简单的称为延迟调度的策略,它会在 framework 中等待指定的时间来获得节点保存的输入数据,产生接近最优的数据局部性。
Mesos 的特性
- 使用 ZooKeeper 复制 master 以实现容错
- 可以扩展上千台节点
- 使用 Linux 容器将任务隔离
- 多种资源的调度(内存和 CPU 等)
- 支持 JAVA、Python 和 C++ API 以部署并行应用
- 查看集群状态的 Web UI
有一些软件项目可以构建在 Apache Mesos 之上:
长期运行的服务
- Aurora 是一个运行在 Mesos 之上的服务调度器,允许您利用 Mesos 的可扩展性、容错性和资源隔离行运行一些需要长期运行的服务。
- Marathon 是一个构建在 Mesos 上的个人 PaaS。它会自动地处理硬件或软件的故障,并保证应用“总是可用“的。
- Singularity 是一个用于运行 Mesos 任务的调度器(HTTP API 和 web 接口):长期运行的进程、一次性任务以及调度作业。
- SSSP 是一个简单的 web 应用,它为在 S3 中存储或共享文件提供了一个白标签 “Megaupload”。
大数据进程
- Cray Chapel 是一个富有创造性的并行编程语言。Chapel Mesos 调度器可以让您在 Mesos 上运行 Chapel 程序。
- Dpark 是 Spark 的一个 Python clone,是一个用 Python 写的类 MapReduce 框架,运行在 Mesos 上。
- Exelixi 是一个用于大规模运行遗传算法的分布式框架。
- Hadoop :通过一个完整的集群在 Mesos 分布式 MapReduce 作业中高效地运行 Hadoop。
- Hama 是一个基于 Bulk Synchronous 并行计算技术分布式计算框架,用于进行大规模科学计算,如矩阵、图形和网络算法等。
- MPI 是一个消息传递系统,设计于使用在各种各样的并行计算机上。
- Spark 是一个快速并具有多种用途的集群计算系统,它使得并行作业易于写入。
- Storm 是一个分布式的实时计算系统。Storm 使我们能够很容易地可靠地处理无界的数据流、实时处理 Hadoop 所批量处理的数据。
批量调度
- Chronos 是一个分布式的支持复杂作业拓扑的作业调度器。它可以作为 cron 的容错性更好的替代品来使用。
- Jenkins 是一个持续集成服务器。mesos-jekins 插件允许其在 Mesos 集群中根据工作负载动态地启动工人进程。
- JobServer 是一个分布式作业调度器和处理器,它允许开发者们使用点和点击 web 界面来构建自定义的批量处理任务对列。
- Torque 是一个分布式资源管理器,提供批处理作业和分布式计算节点的控制。
数据存储
- Cassandra 是一个高可用分布式数据库。商品硬件或云基础设施中的线性可扩展性和经过证实的容错性使它成为关键任务的最佳平台。
- ElasticSearch 是一个分布式搜索引擎。Mesos 使它可以易于运行和扩展。
- Hypertable 是一个高性能、可扩展、分布式的存储和处理系统,用于结构化和非结构化数据。
总结
流行趋势如云计算和大数据,正在将组织从联盟中移出,并进入了拥有多种分布式系统来专门处理特定任务的情况。有了 Docker executor 对 Mesos 的帮助,Mesos 可以结合 Chronos 和 Marathon 框架运行和管理 Docker 容器。Docker 容器提供了一个一致、紧凑和灵活的打包应用的方法。使用 Mesos 上的 Docker 交付应用程序承诺了一个真正弹性、高效和一致的平台,以在云中或其前提下交付一些列应用程序。